Observability is often fragmented: logs in one tool, metrics in another, traces missing, unclear ownership, and reactive incident handling that pushes MTTR up and SLA confidence down.
- • No single view across logs/metrics/traces
- • High alert noise and weak routing
- • RCA is slow and inconsistent
A unified platform that ingests logs, metrics and traces, defines SLOs and alert policies, detects incidents automatically, and provides RCA dashboards for ops and executives.
- • Correlation by service, tenant, request-id
- • SLOs, error budgets and paging policy
- • RCA evidence that’s reusable and auditable
Correlate logs/metrics/traces across services with consistent identifiers and context—so issues can be understood fast.
Define SLOs, error budgets and alert policies to keep SLAs measurable and predictable.
Detect anomalies, correlate signals and reduce noise with smart routing and deduplication.
RCA dashboards linking incidents to services, deployments, costs and performance regressions—shareable across teams.
Architecture
Distributed systems emit logs, metrics and traces. The platform correlates signals into unified monitoring, SLO alerting and automated incident detection—then exposes RCA outputs for ops teams and leadership dashboards.
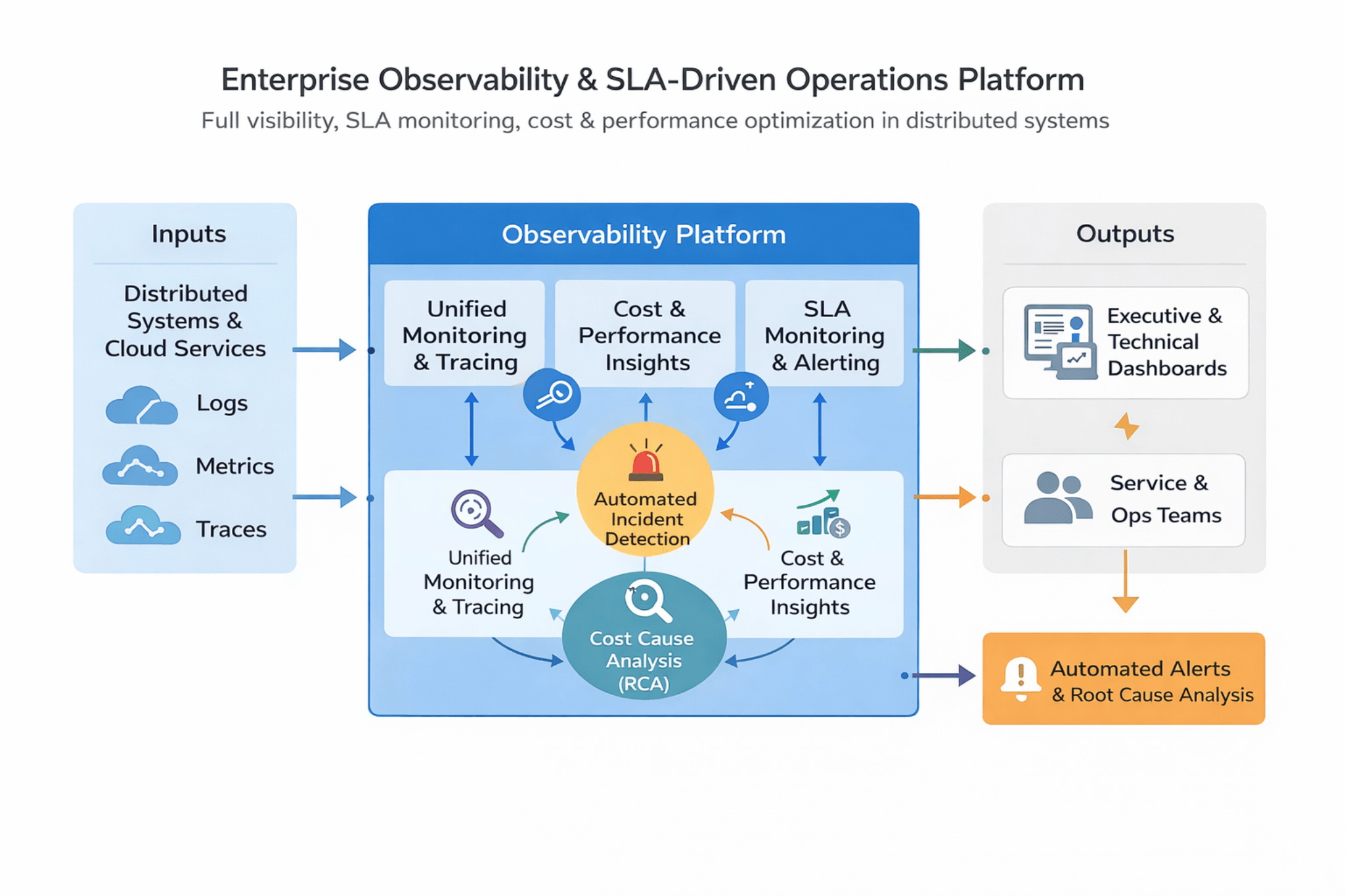
Logs, metrics and traces from cloud services and distributed systems.
Unified monitoring, SLO alerting, incident detection and RCA.
Dashboards, service/ops workflows, automated alerts and RCA reports.
Want predictable operations and measurable SLAs?
We tailor SLOs, alerting, correlation and reporting to your environment—aligned with enterprise controls and governance.
Response within 24h · NDA available · EU-based delivery